배열과 연결리스트에 대해 알아보자 🤗
안녕하세요! 두두코딩 입니다 ✋
오늘은 선형 자료구조와 연결형 자료구조 개념에 대해 알아보겠습니다.
해당 포스팅은 코딩테스트를 위한 자료구조와 알고리즘 with C++ 책을 참고하여 작성되었습니다.
🖇 소스코드에 마우스를 올리고 copy 버튼을 누를 경우 더 쉽게 복사할 수 있습니다!
궁금한 점, 보안점 남겨주시면 성실히 답변하겠습니다. 😁
+ 감상평 댓글로 남겨주시면 힘이됩니다. 🙇
들어가며
응용프로그램을 설계할 때 가장 중요하게 고려되어야 할 부분은 바로 데이터 관리이다. 보통 데이터를 입력받아 처리한 후 저장하고, 필요할 때 불러쓰는 방식으로 사용된다.
예를들어 생각해보자.
우리가 병원관리 시스템을 만들었다고 생각해보면, 저장해야될 데이터가 의사와 환자, 처방전, 보관기록 등이 있을 것이다. 관리시스템은 환자를 입원 시키는 것을 할 수 있어야하고, 의사를 고용하거나 해고하는 경우 등을 관리할 수 있어야한다. 이를 효율적으로 하기 위해서는 시스템 내부적으로 체계적인 “데이터 관리”가 가능해야한다.
보통 프로그래머는 데이터를 저장하기 위해 여러가지 자료구조를 사용한다. 동작 성능과 안정성을 위해 적절한 자료구조를 사용해야하며, 데이터를 조작에 적합한 알고리즘을 사용하는 것이 필수적이다. 따라서, 프로그래머는 자료구조와 알고리즘을 필수적으로 공부해야한다.
차근차근 알아보자.
Tip 우리가 어떤 상황에 어떤 알고리즘을 사용해야하는가에 대한 판단 기준은 보통 복잡도로 많이 한다. 복잡도는 공간 복잡도, 시간 복잡도, 알고리즘 복잡도 등이 있는데, 보통의 판단 기준은 “시간 복잡도”로 많이 하게 된다. 시간복잡도란 특정 작업을 수행할 때 소요되는 시간을 나타낸 것을 말한다.
선형자료구조
우리는 C++에서 가장 보편적으로 사용되는 “선형 자료구조”에 대해서 먼저 알아볼 것이다.
선형자료구조는 크게 “연속된 자료구조” 와 “연결된 자료구조” 두 가지로 나뉜다.
🌱 연속된 자료구조
연속된 자료구조는 모든 원소를 단일 메모리 청크에 저장한다. 아래의 그림을 보자.
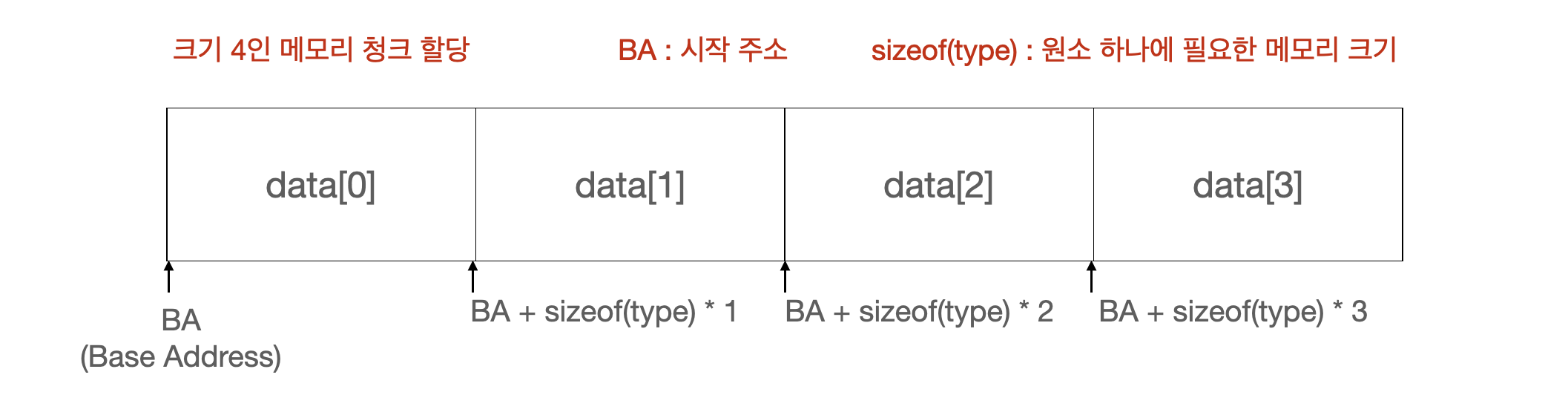
바깥 쪽 큰 사각형은 “단일 메모리 청크”를 나타낸다. 그리고 안쪽의 4개의 사각형은 각각 메모리 공간을 나타낸다. 각 사각형의 타입은 동일하다. 따라서, 모든 메모리 공간은 같은 size를 갖고 있다고 볼 수 있으며, 접근하기 위해서는 기준이 되는 BA (Base Address)를 시작점으로 size(type) * i 만큼 움직여 접근이 가능하다.
이러한 선형 자료구조를 우리는 배열이라고 부르며, 배열은 전체 크기에 상관 없이 BA를 기준으로 원소에 직접 접근이 가능해진다. 따라서, 데이터 접근시간이 일정하며, 시간복잡도로는 O(1) 이라고 표현한다.
배열의 유형은 정적배열 과 동적배열 2가지로 나뉘게된다.
- 정적배열은 선언된 블록이 끝나면 소멸된다.
- 동적배열은 프로그래머가 생성할 시점과 소멸할 시점을 고려해 사용해야된다. (즉, 블록이 끝났다고 소멸되지 않는다.. 😲)
배열의 선언방법은 다음과 같다.
int arr[size]; // 정적배열 선언
int* arr = (int *)malloc(size*sizeof(int)); // C style 동적배열 선언
int* arr = new int[size]; // C++ style 동적배열 선언
두 가지 유형 모두 데이터에 접근할 때, 동일한 성능을 나타낸다. 하지만, 배열의 가장 큰 단점으로는 데이터를 삭제하고 삽입할 때 나타난다. 단일 메모리 청크로 되어져있기 때문에, 특정 위치에 데이터를 삽입하게 될 경우 전체의 배열을 밀어내야하고, 삭제하게 되면 그만큼 전체 메모리 청크를 당겨야한다. 아래의 그림을 보자.
- 삭제와 삽입 그림 추가
Tip 배열과 같은 연속된 자료구조에서 각 원소는 서로 인접해 있기 때문에 하나의 원소에 접근할 떄, 그 옆에 있는 원소도 함께 캐싱해 가져온다. 따라서, 주변에 접근할 때 매우 빠르게 접근이 가능하다. 이러한 속성을 우리는 “cache locality (캐시 지역성)”이라고 부른다.
🌱 연결된 자료구조
연결된 자료구조는 노드 라는 여러개의 메모리 청크에 데이터를 저장한다. 이 경우 서로 다른 메모리 위치에 데이터가 저장되게 된다. 아래의 그림을 보자.

위와 같이 연결된 자료구조를 우리는 연결 리스트라고 부른다.
연결 리스트의 기본 구조는 각 노드에 저장할 데이터를 담고 다음 위치를 가리키는 포인터를 갖고 있다. 연결리스트에서 특정 노드에 접근하기 위해서는 가장 처음 HEAD 노드 부터 쭉 탐색해 i번을 찾는다. 만약 n번쨰에 있다면 n번의 노드를 탐색해야한다. 따라서 시간 복잡도는 O(n) 이라고 할 수 있다.
우리가 위에서 봤던 배열의 문제점을 연결리스트에서는 쉽게 해결할 수 있다. 위에서 우리는 배열에 원소이 삽입과 삭제를 할 때, 비효율이 발생하기 때문에 문제점이라고 지적했다. 연결리스트는 삽입, 삭제를 큰 어려움 없이 할 수 있다. 아래의 그림을 보자.
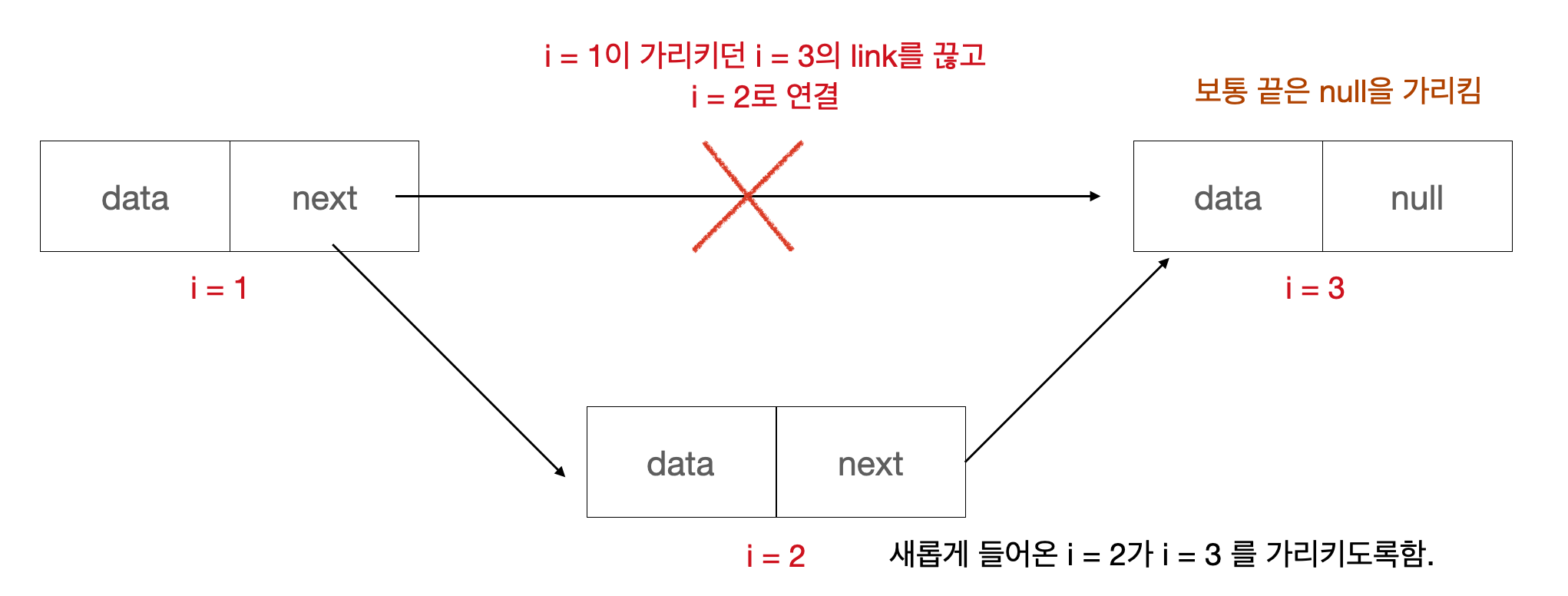
새로운 원소를 삽입한다고 가정할 때, 우리는 새로운 노드가 들어가야할 위치를 찾는다. 예를들어, (i=2)가 들어온다고 가정하면, (i=1), (i=3) 사이에 들어가야한다. 따라서, (i=1)이 가리키고 있던 (i=3)의 포인터를 제거해 (i=2)을 가리키게 하고, (i=2)은 (i=3)을 가리키도록 한다. 이렇게 해주면 데이터 삽입이 완료 된 것이다.
배열과 달리 모든 데이터를 줄이고 늘리고 할 필요 없어서 아주 빠르게 삽입/삭제를 처리할 수 있다.
Tip 우리가 위에서 배운 캐시지역성 개념이 연결리스트에는 적용되지 않는다. 따라서, 배열과 연결리스트가 모든 요소를 찾는다고 하면 이론적으로는 같은 성능이 나와야한다. 하지만 실제로는 배열에서 캐시지역성 동작으로 인해 연결리스트보다는 좋은 성능을 낸다는 점을 알아두자.
두 자료구조의 비교
아래의 표는 우리가 분석했던 자료구조들의 비교표이다. 읽어보면서 다시 한번 이해해보기 바란다.
| 연속된 자료구조 | 연결된 자료구조 |
|---|---|
| 모든 데이터가 메모리에 연속적으로 저장 | 데이터는 노드에, 노드는 메모리 곳곳에 흩어짐 |
| 임의 원소에 즉각 접근 가능 | 임의 원소에 접근하는 것은 선형 시간 복잡도를 가짐 (느림) |
| 데이터가 연속적으로 저장되어있고, 캐시지역성 효과로 모든 데이터를 순회하는 것이 매우빠름 | 캐시지역성 효과가 없어 모든 데이터를 순회하는 것이 느림 |
| 데이터 저장을 위해 정확하게 데이터 크기만큼의 메모리 사용 | 각 노드에서 포인터 저장을 위해 여분의 메모리를 사용 |
배열과 연결리스트는 매우 범용적이며, 많은 응용 프로그램에서 데이터를 저장하는 용도로 사용한다. 따라서, 이들 자료구조에는 버그가 없어야하고 최대한 효율적으로 동작해야한다.
C++에서는 사용자가 직접 구현하지 않아도 “배열”과 “연결리스트”를 사용할 수 있도록 std::array, std::vector 그리고 std::list와 같은 자료구조 클래스를 제공한다.

