Protected 접근권한에 생성자와 소멸자를 만드는 이유를 알아보자👏
C++ 디자인 패턴 강의를 듣고 정리하고자 합니다. 자세한 내용은 여기를 클릭해주세요.
궁금한 점, 보안점 남겨주시면 성실히 답변하겠습니다. 😁
+ 감상평 댓글로 남겨주시면 힘이됩니다. 🙇
Protected 생성자
우리는 보통 default 생성자 혹은 일반 생성자를 생성할 때, public 접근권한에
정의해 구현하곤 한다. 하지만, 오픈 소스를 보면 생성자를 protected 접근권한에
두는 경우가 종종 존재한다. 많은 이유가 있겠지만, Design 관점에서 생각해보자.
#include <iostream>
using namespace std;
class Animal
{
protected:
Animal() {}
};
class Dog : public Animal
{
public:
Dog() {}
};
int main()
{
// 외부에서 접근 불가능
Animal a; // error
Dog d; // Ok
}
C++을 배웠던 사람이라면, “객체 호출 시 생성자가 불림” 이라는 내용을 알 것이다. 특히, 아무것도 만들지 않으면 컴파일러가 객체를 만들어 줄 것이라는 것도 알고, 만약 사용자가 정의 하면 해당 default 생성자는 만들어지지 않고 사용자가 만든 생성자를 호출하도록 할 것이다. 라는 개념을 알고 있을 것이다. (몰라도 괜찮다 지금 알면 되니까..🤔 기초 강의 정리를 할때 한번 더 언급하겠다.)
위의 예시를 보면, Dog라는 객체는 Animal 객체를 상속 받아 만들어진다. Animal 객체는 생성자가 protected로 선언되어져 있어 외부에서 부를 경우 compiler가 잘 못 됐다고 에러를 출력한다. 반면에 Dog 객체를 생성할 경우 정상 동작한다.
흔히 우리는 encapsulation을 위해 접근 제한자를 활용하라고 배웠다. 왜 외부에서 부르지 못하는 영역 protected에 생성자를 넣는 것일까? 그리고 왜 자식 객체인 Dog 객체는 에러가 발생하지 않을까? 보통 자식 객체를 생성하면 “부모생성자” -> “자식 생성자” 순으로 불리는데, 부모 생성자가 protected인데 왜 에러가 나지 않을까? 🤔 이제부터 알아보자.
Compiler 호출 순서
우리가 흔히 자식객체를 호출 할 때, 부모 생성자 불리고, 자식생성자 불린다 라는 이야기를 많이한다. 실제 코드의 결과 값으로 봐도 “부모” -> “자식” 순서로 불리는 것을 확인할 수 있다. 하지만, 해당 결과는 반쪽짜리 답만 가지고 있다고 볼 수 있다.
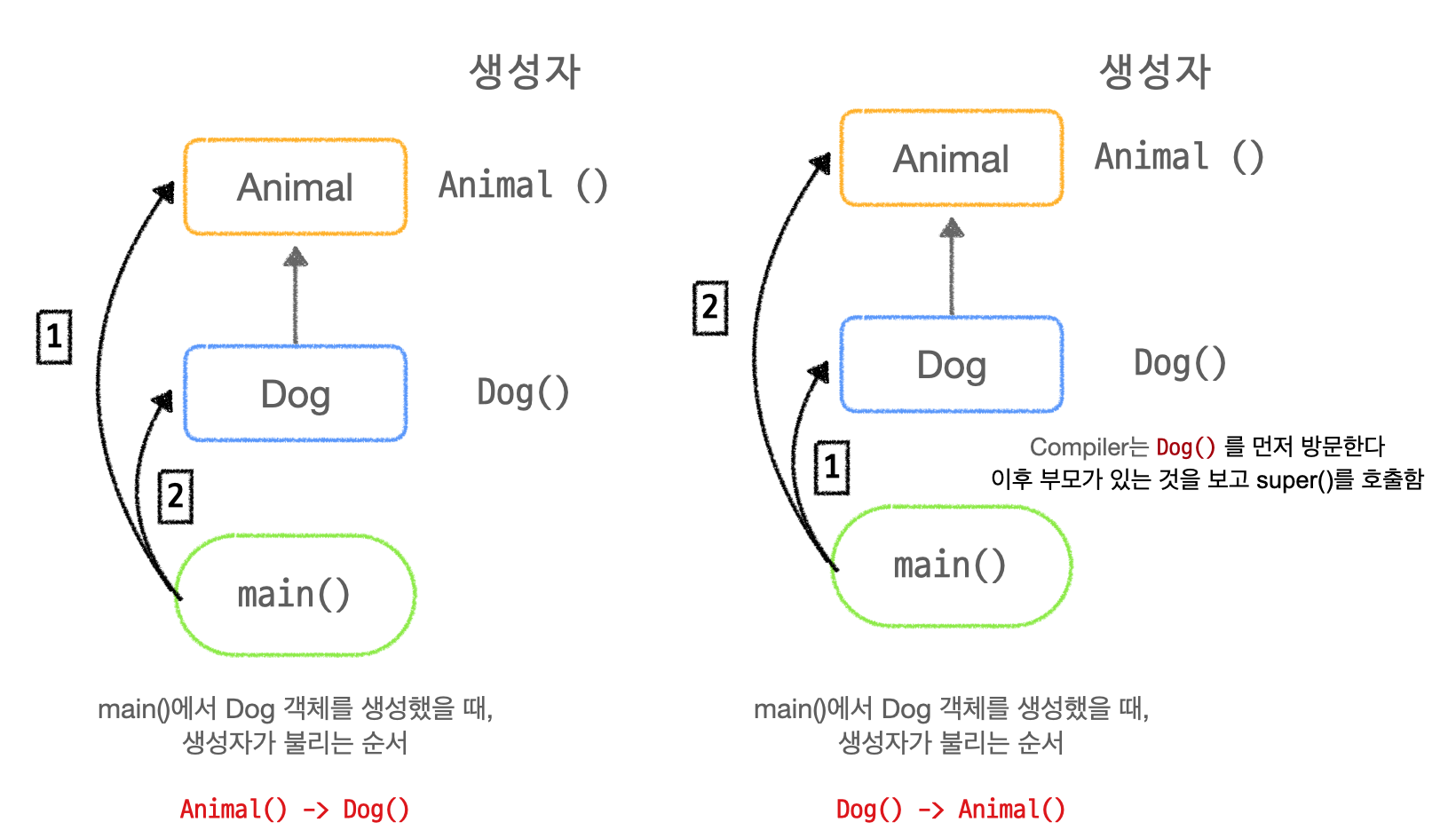
위의 그림을 통해 확인해보자.
위의 그림을 보면 왼쪽 그림은 흔히들 생각하는 그림이다. 하지만, 우리가 compiler가 되었다고 가정하고 보면, 실제 코드동작은 오른쪽 그림과 같이 생각해야한다.
즉, compiler가 main()에서 Dog라는 객체를 생성할 경우 우선 Dog라는 객체를
만들기 위해 Dog객체 생성자 쪽으로 호출 된다. 이때, compiler는 Dog 객체가
: Animal 즉, 상속을 받아서 만들어 졌구나 라는 것을 알게 되고 super() 즉,
부모 객체의 생성자를 불러준다.
여기서 중요한 점이 `Dog` 객체는 `Animal`의 파생 클래스 이기 때문에 `protected`
영역에 접근할 수 있다. 따라서, "부모 생성자" -> "자식 생성자" 순으로 결과를
내놓으면서 정상 동작하게 된다.
이 절의 핵심 포인트는 compiler의 동작 순서이다. compiler가 상속을 받았다고
바로 Dog가 아닌 Animal 객체를 생성하고자 한다면 에러를 만났을 것이다.
(외부에서 접근이 불가능하니..) 하지만 순서가 Dog부터 불리고 이후 Animal을
부르기 때문에 정상동작한다는 사실을 잊지말자.
protected 생성자를 만드는 이유
우리는 위의 compiler 호출 순서로 부터 protected 생성자를 만들 경우
“외부에서는 자기 자신을 만들 수 없지만, 파생 클래스들 (자식)들은 만들 수 있도록
하겠다” 라는 사실을 유추하게 됐다.
왜 이런 생성자를 만들어야 할까? (Design 관점에서 봐라보자 💇)
현실세계의 디자인을 그대로 옮긴 것이 객체 지향언어이다. 객체지향 디자인
관점에서 보자면, protected 생성자는 너무 당연한 이야기이다.
우리가 Animal (동물) 을 물체 혹은 생명체와 같은 객체화 하지 않는다. 즉, Animal은 하나의 추상적인 개념에 불가하다. 하지만, Dog (멍멍이 🐶) 현실에 존재하는 하나의 모델이자 객체이다. 따라서, 객체로 만들 수 있도록 해야한다.
protected 생성자를 만드는 이유 는 현실세계에 없는 것 (추상 개념)을 만들어
사용할 때, protected 를 이용해 만들어야하기 때문이다. 요새는 언어가 많이
발전해서 다른 키워드가 존재할 수 있다. 하지만, “openSource”에서는 기존 legacy
code들을 가지고 가기 때문에 해당 design을 만날 수 있으니 꼭 기억해두자.
앞으로 우리가 상속을 봐라 볼 때, 컴파일러 순서 와 해당 객체가 추상적인지를 확인하는 습관을 기르자. 마냥, 부모클래스 함수 쓸 수 있구나로 생각하지만 말고.. 🙄
protected 소멸자
proected 소멸자는 객체의 수명을 관리할 때, 참조기반계수로 할 경우가
존재하는데 (즉, 누가 사용하고 있어 자원이 소멸되지 않는 상태 확인하는 경우) ,
해당 경우 protected 소멸자를 사용한다.
#include <iostream>
using namespace std;
class Car
{
public:
Car() {}
void Destory() { delete this; }
protected:
~Car() { cout << "~Car" << endl; }
}
int main()
{
// Car c; // 스택에 객체를 만들 수 없게 해둠
Car *p = new Car;
p->Destroy();
// delete p; // 소멸자 부르지 못해 Error
}
protected 소멸자를 생성할 경우 “어떤 객체가 파괴 될 때 소멸자를 외부에서
부르지 못하게 해라.” 라는 의미이다.
해당 소멸자를 쓸 경우 memory Stack영역 에 객체를 생성할 수 없게 된다. 우리가
일반적으로 객체를 사용할 때, Car c;와 같은 방식으로 정의한다. 해당 객체는
메모리 영역 중 Stack 영역에 적제되고 객체가 사용된다. 이후 main() 혹은
객체를 사용중인 함수를 벗어날 때, 자동으로 소멸자를 불러 객체를 파괴
시켜준다. 하지만, 소멸자 자체가 protected 영역에 존재하기 때문에 자동으로
소멸자를 부를 수 없도록 한다. 즉, 해당 객체는 Stack영역 에서 사용하지 말라는
시그널을 주는 것이다. 🤓
객체를 Stack영역에 만들지 못하면 어떻게 해야되는가? 🤔
이 문제를 해결하기 위해선 memory Heap영역 을 사용해야한다. 우리가 흔히
사용하는 new 키워드로 객체를 Heap 영역에 만들어 사용해야한다. Heap 영역
같은 경우 자동으로 소멸자를 부르지 않는다. 따라서, 자원을 해제하지 않으면 낭비
하는 문제가 있지만, 해제 하지 않았다는 것은 아직 객체 사용 중 이라는 말이다.
(참조 계수 기반으로 객체가 얼마나 살아있는지 관리 가능)
만약 Heap 영역 에 있는 객체를 해제시키기 위해서는 delete키워드를 통해 자원을
해제해야한다. 하지만, delete 키워드를 main()과 같은 외부에서 직접적으로
사용할 경우 protected 영역에 접근하지 못하기 때문에 에러가 발생하게 된다.
따라서, 외부에서 접근가능 한 member 함수 (Destory 함수)를 하나 만들어
외부에서 객체 사용이 끝날 경우 호출해주도록 한다.
Appendix
해당 키워드를 사용하는 방법들에 대한 이유는 여러가지가 존재할 수 있다. 여기서는 Design 관점위주로 봐라 본다는 사실을 기억하자.
그리고, 해당 내용을 볼 때, 너무 모르는 영역이 많다면, 시중의 C++ 책을 아무거나 사서 한번 읽어보고 접근해보자. (여기서는 상속 내용과 같은 일반적 내용들은 안다고 가정하고 포스팅 하기 때문에.. 초심자에겐 약간 어려울 수 있다.😢 )
다소 내용이 긴 것 같지만, 핵심은 2가지 이니 차근차근 읽어보고 따라 쳐보기 바란다! 🤗