고득점 kit 입국심사 문제를 이분 탐색을 활용해 풀어보자 🤓
안녕하세요! 두두코딩 입니다 ✋
오늘은 고득점 Kit 문제 중 입국심사 문제를 풀어봅시다.
🖇 소스코드에 마우스를 올리고 copy 버튼을 누를 경우 더 쉽게 복사할 수 있습니다!
궁금한 점, 보안점 남겨주시면 성실히 답변하겠습니다. 😁
+ 감상평 댓글로 남겨주시면 힘이됩니다. 🙇
문제
해당 문제는 프로그래머스의 고득점 kit의 문제입니다.
문제는 여기를 클릭해 확인해주세요!
풀이
해당 문제는 모든인원들을 입국심사하는데 걸리는 최소시간을 구하는 문제이다. 해당
문제는 이분탐색을 통해 해결 할 수 있다.
접근과정
심사위원의 처리 시간을 고민해보자. 우선 가장 짧게 걸릴 수 있는 시간은 얼마일까? 사람이 한명 들어온다고 가정하고, 1분만에 심사를 할 수 있는 심사위원이 있을 경우이다. 그렇다면 가장 긴 시간은 얼마일까? 가장 긴시간은 “심사위원 중 심사를 가장 느리게 하는 심사위원에게 모든 사람이 몰리는” 경우이다.”
즉, 수식으로 표현해보면, 처리를 가장 느리게하는 심사위원 속도 * n명의 사람들이다.
위의 접근과정을 통해 최소 시간과 최대 시간을 알게되었다. 해당 값을 이용해서
이분탐색을 진행한다. 이분탐색은 최소값과 최대값을 절반으로 나누고 해당 값이
동일한지, 작은지, 큰지 를 판단한다. (좀 더 자세한 내용은 이분 탐색 알고리즘을
찾아보자!😵)
해당 논리를 그림으로 표현해 보았다.
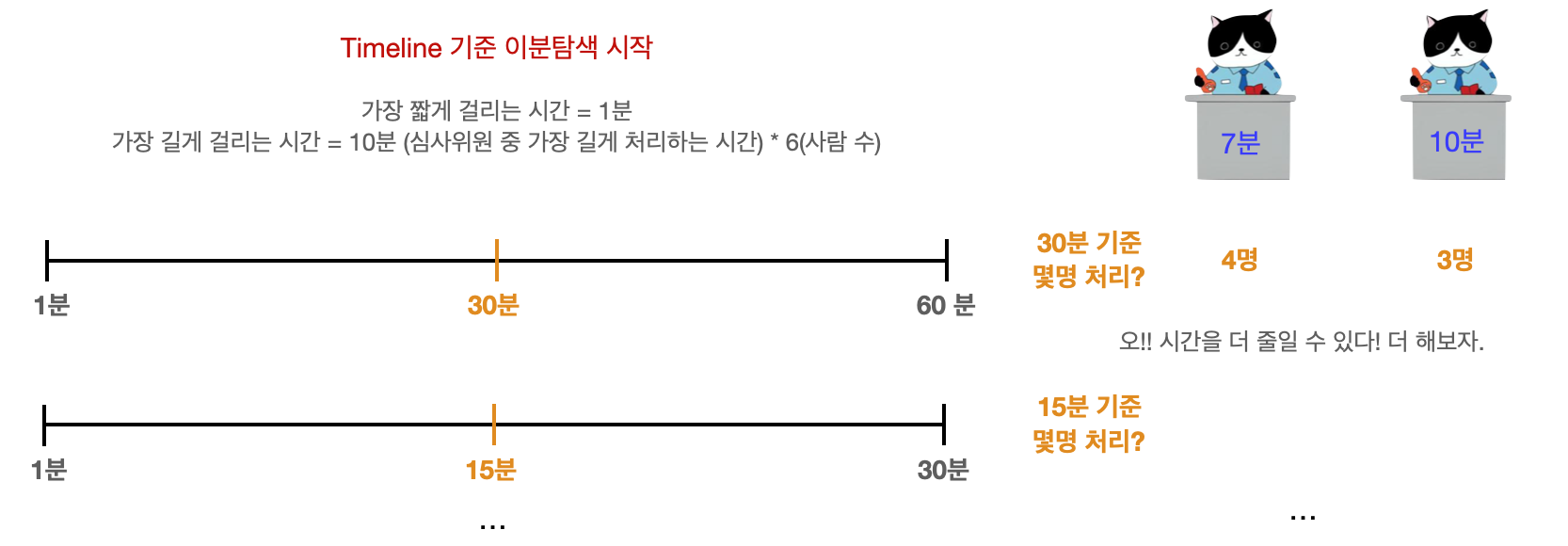
위의 그림은 문제의 예시기반으로 논리를 그림으로 표현한 것이다. 우선, 가장 짧은 시간은 1분이고, 가장 긴 시간은 아마 10분 심사위원한테 모든 사람이 몰리는 60분 일 것이다.
최소값 1분과 최대값 60분 기준으로 이분탐색을 진행한다. 값을 반으로 나눴을 때,
해당 값에 심사위원들이 처리할 수 있는 사람 수를 구한다. 예를들어, 30분일 때는
7분 심사위원은 4명, 10분 심사위원은 3명을 처리할 수 있다. 우리는 문제에서
최소 시간으로 모든 사람을 처리해야하기 때문에 시간을 더 줄일 수 있다.
더 최소를 구해보기 위해 현대 이분탐색의 결과를 최대값으로 두고 계속해서
이분탐색을 진행한다. 최대시간과 최소시간이 바뀔때까지 진행하면 우리가
원하는 입국심사의 최소시간을 구할 수 있을 것이다.
해당 문제에서 핵심은 데이터가 엄청나게 많다는 점이다. 따라서, C++ 같이 데이터
타입이 있는 형태의 언어는 꼭 주의해서 사용하자. C++에서는 왠만한값을 long
long으로 변환하고 풀면 마음이 편할 것이다. 다만, 현업에서는 메모리를
아껴야하기 때문에 long long의 남발은 좋지 못할 것이다. 하지만, 문제풀때는 적극
활용하자!😎
소스코드
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
long long solution(int n, vector<int> times) {
long long answer = 0;
sort(times.begin(), times.end());
long long min = 1;
long long max = n * (long long)times.back();
while (min <= max) {
long long avg = (max + min) / 2;
long long tmp = 0;
for (int i = 0; i < times.size(); i++) {
tmp += (avg / (long long) times[i]);
}
if (tmp >= n) {
max = avg - 1;
answer = avg;
}
else min = avg + 1;
}
return answer;
}
Appendix
주석을 추가한 소스코드이다.
/**********************
해당 문제 조건
* 입국심사를 기다리는 사람은 1명 이상 1,000,000,000명 이하입니다.
* 각 심사관이 한 명을 심사하는데 걸리는 시간은 1분 이상 1,000,000,000분 이하입니다.
* 심사관은 1명 이상 100,000명 이하입니다.
**********************/
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
long long solution(int n, vector<int> times) {
long long answer = 0;
// 가장 큰 값을 뽑기 위해 정렬
// 해당 함수는 max_element()를 사용해도 됨.
sort(times.begin(), times.end());
long long min = 1;
// 주의. 데이터타입
long long max = n * (long long)times.back();
/* 이분탐색 */
// 최대값과 최소값이 바뀌는 구간이 가장 최소 시간이다.
while (min <= max) {
long long avg = (max + min) / 2;
long long tmp = 0;
// 현재 시간 기준으로 심사위원들이
// 몇명을 처리하는지 확인하는 부분
for (int i = 0; i < times.size(); i++) {
tmp += (avg / (long long) times[i]);
}
// 현재 값 보다 많은 사람을 처리할 수 있을 경우
if (tmp >= n) {
max = avg - 1;
answer = avg;
}
// 현재 값보다 적은 사람을 처리할 수 있을 경우
else min = avg + 1;
}
return answer;
}
해당 코드에서는 주의. 데이터타입 부분을 잘 확인해야한다. C++에서는 데이터
타입을 엄격하게 지키는데, int * int를 할경우 int 값을 뽑고, long long
타입에 값을 넣는다. 즉, int * int 할 때, 데이터의 overflow가 발생할 수 있으며,
발생한 이후의 값이 long long으로 들어가기 때문에 값이 정확히 구해지지 않을
수도 있다. 혹시 풀었는데 값이 이상하게 틀릴 경우 여기를 확인해보자.
추가로, vector 내에서 가장 큰 원소를 찾을 때, 정렬 후 마지막 값을 뽑아도
되지만, max_element()라는 함수를 이용해도 된다. 이점을 기억하고 추가로
써보도록 하자!

